
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- deepseek
- MySQL
- dfs
- 가상환경
- 연구
- SQL
- 알고리즘
- leetcode
- 그래프
- 머신러닝
- Aspect
- LLM
- paper review
- 분산
- 코딩테스트
- ChatGPT
- Bert
- 프로그래머스
- NLP
- 파이썬
- gpt1
- transformer
- GPT
- join
- 자연어처리
- SQL 첫걸음
- outer join
- ABAE
- 논문리뷰
- 백준
- Today
- Total
huginn muninn
오차행렬(confusion matrix) 본문
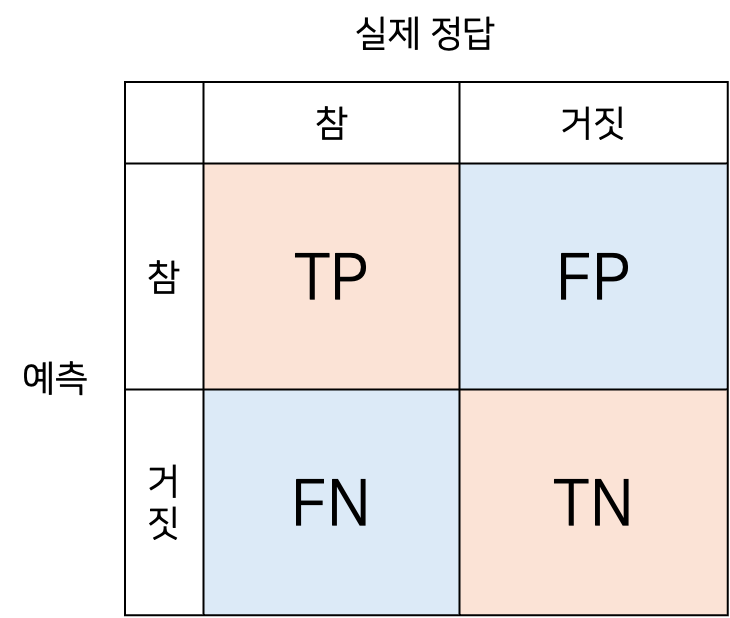
이진 분류에서 성능 지표로 잘 활용되는 오차행렬은 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지 함께 보여주는 지표이다.
즉 이진 분류의 예측 오류가 얼마인지와 더불어 어떠한 유형의 예측 오류가 발생하고 있는지를 함께 나타내는 지표이다.

처음 공부할 때 TP, TN, FP, FN이 헷갈려서 위와 같이 정리해보았다.
앞에 위치한 T, F는 실제로 정답을 맞추었는지를 의미하는 것으로, 아래 예시로 설명할 수 있다.
- TP : 실제로 비가 왔는데, 모델이 비가 온다고 함.
- TN : 실제로 비가 안왔는데, 모델이 비가 안 온다고 함.
TP,TN,FP,TN 값은 classifier 성능의 여러 면모를 판단할 수 있는 기반 정보를 제공한다. 이 값을 조합해 Classifier의 성능을 측정할 수 있는 주요 지표인 정확도, 정밀도, 재현율 값을 알 수 있다.
1. 정확도
정확도는 아래와 같은 식으로 구할 수 있다.
정확도=(TN+TP)/(TN+FP+FN+TP)
일반적으로 이러한 불균형한 레이블 클래스를 가지는 이진 분류 모델에서는 많은 데이터 중에서 중점적으로 찾아야 하는 매우 적은 수의 결과값에 Positive를 설정해 1값을 부여하고, 그렇지 않은 경우는 Negative로 0값을 부여하는 경우가 많다.
예를 들어 사기행위 예측모델에서는 사기 행위가 Positive 양성으로 1, 정상행위가 Negative 음성으로 0값이 결정값으로 할당되거나 암 검진 예측 모델에서는 암이 양성일경우 Positive 양성으로 1, 암이 음성일 경우 Negative 음성으로 0값이 할당되는 경우가 일반적이다.
불균형한 이진 분류 데이터 세트에서는 Positive 데이터 건수가 매우 작기 때문에 데이터에 기반한 ML알고리즘은 Positive보다는 Negative로 예측 정확도가 높아지는 경향이 발생한다.
결과적으로 정확도 지표는 비대칭적인 데이터 세트에서 Positive에 대한 예측 정확도를 판단하지 못한 채 Negative에 대한 예측 정확도만으로도 분류의 정확도가 매우 높게 나타나는 수치적인 판단 오류를 일으키게 된다.
정확도는 분류 모델의 성능을 측정할 수 있는 한 가지 요소일 뿐이다 불균형한 데이터 세트에서 정확도만으로는 모델 신뢰도가 떨어질수 있다.
2. 정밀도, 재현율
정밀도와 재현율은 positive 데이터 세트의 예측 성능에 좀 더 초점을 맞춘 평가 지표이다.
2-1. 정밀도

정밀도 = TP / (FP+TP)
정밀도는 '예측'을 기준으로 계산한다.
예측을 참으로 한 것 중, 실제로 정답이 참인 것의 비율이다.
2-2. 재현율
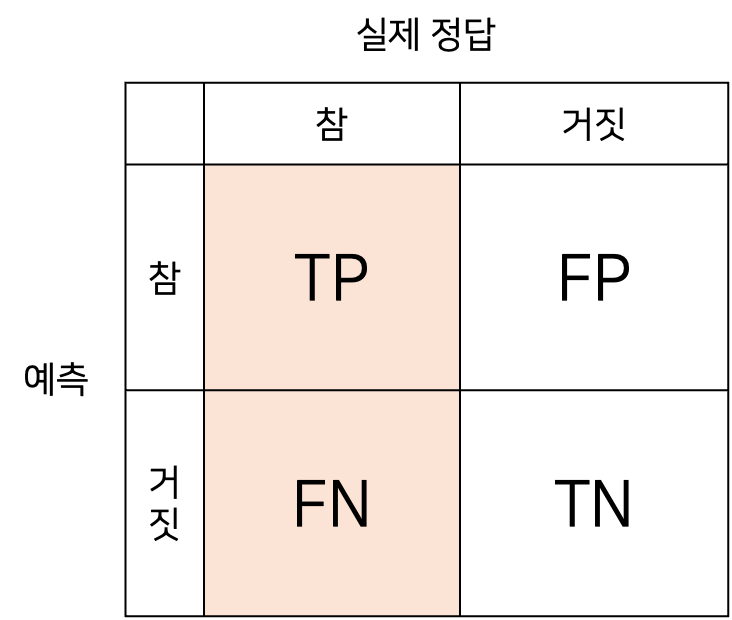
재현율 = TP / (TP+FN)
재현율은 '실제 정답'을 기준으로 계산한다.
실제 정답이 참인 것 중, 예측을 참으로 한 것의 비율이다.
정밀도와 재현율 지표 중에 이진 분류 모델의 업무 특성에 따라서 특정 평가 지표가 더 중요한 지표로 간주될 수 있다.
재현율이 중요 지표인 경우는 실제 정답이 참인 것을 거짓으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우이다.
ex) 암 판단 모델일 경우 재현율이 훨씬 중요하다. 실제 참인 암환자를 참이 아닌 거짓으로 잘못 판단했을 경우 오류의 대가가 생명을 앗아갈 정도로 심각하기 때문...!
'머신러닝' 카테고리의 다른 글
| 다중공선성(Multicollinearity) (0) | 2024.04.07 |
|---|---|
| 머신러닝을 위한 수학적 개념 이해 (1) | 2024.04.04 |
| 모형의 적합성 평가와 과적합(overfitting) (1) | 2024.04.03 |
| Machine Learning의 개념과 종류 (0) | 2024.03.30 |



