| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 프로그래머스
- dfs
- 분산
- LLM
- 파이썬
- 논문리뷰
- deepseek
- leetcode
- ChatGPT
- outer join
- gpt1
- ABAE
- 자연어처리
- 코딩테스트
- NLP
- transformer
- paper review
- Bert
- 머신러닝
- SQL
- 알고리즘
- MySQL
- join
- 백준
- 그래프
- 가상환경
- 연구
- SQL 첫걸음
- Aspect
- GPT
- Today
- Total
huginn muninn
Limitations of Attention and Transformer 본문
가중치 합을 구할 때 Key 정보를 각각 내적하기 때문에 순서정보를 반영하지 못한다.
👁️ 눈을 감으면 네 생각이 나.
🌨️ 눈이 내리는 날 우리 만나.
우리는 이 두 문장을 봤을 때, 첫번째 문장의 눈과 두번째 문장의 눈이 다른 것을 바로 파악할 수 있지만 컴퓨터는 그렇지 못한다.
attention에서는 내적하기 때문에 주변 단어의 맥락을 파악하기가 어렵다. 그래서 Positional Encoding이 등장했다.
Positional Encoding

트랜스포머는 단어의 위치 정보를 얻기 위해 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하는데 이를 포지셔널 인코딩이라고 한다.
임베딩 벡터가 인코더의 입력으로 사용되기 전, 포지셔널 인코딩값이 더해지는 과정을 시각화하면 아래와 같다.

하지만 앞서 보여준 예시처럼 "눈"은 문장 내 순서도 똑같아서 내적과 Positional Encoding 만으로는 서로 다른 뜻이라는 것을 반영할 수가 없다.
이를 위해 self-attention이 포함된 encoder layer를 transformer에서 사용한다. 셀프 어텐션은 본질적으로 query, key, value가 동일한 경우를 말한다. 여기서 동일하다는 말은 벡터의 값이 같다는 것이 아니라 벡터의 출처가 같다.
Transformer의 학습과 Masking
Transformer는 쉽게 말해서 번역기라고 이해하면 쉽다.

Transformer는 앞에서부터 차례대로 번역한다. Lamb을 예측하기 위해서 n-1 번째까지인 “I want to eat”을 decoder에 입력한다.
그럼 첫번째 단어는 뭘 보고 예측할까?
바로 문장의 시작을 뜻하는 토큰인 (start of sequence) [SOS] 을 보고 예측할 수 있다. 문장이 끝났다는 건 (end of sequence)인 [EOS]가 나오면 끝낼 수 있다.
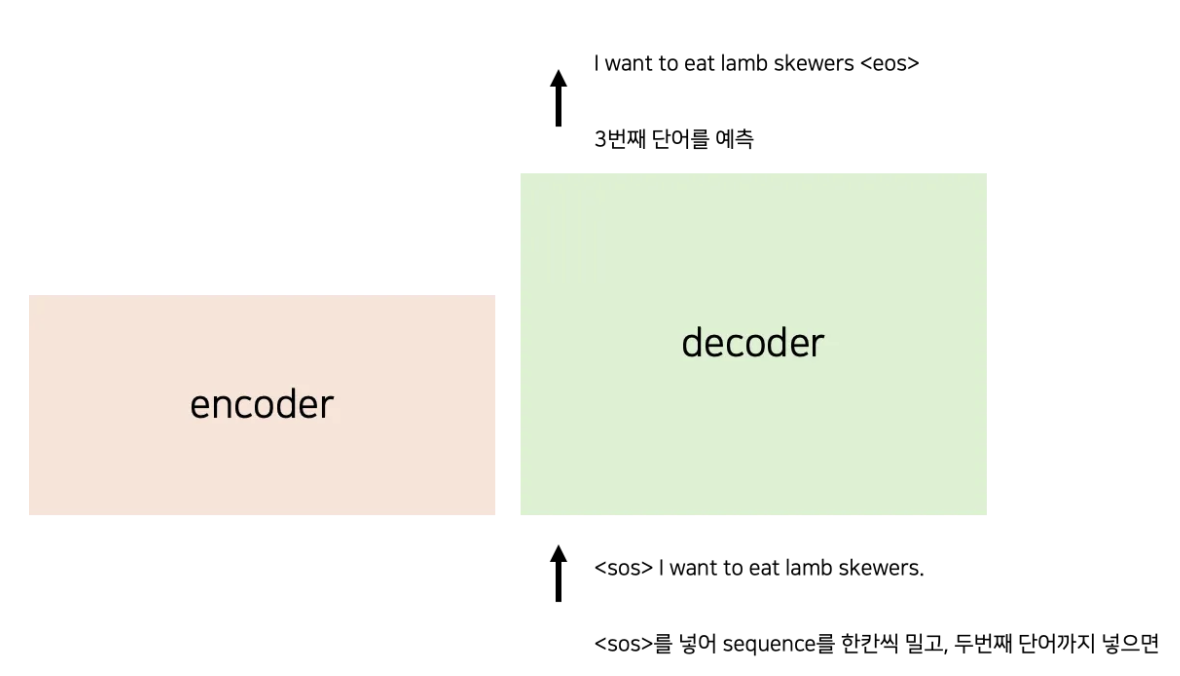
위 그림처럼 한 단어씩 넣지 않고, 디코더에 input에는 <sos>를 넣고, 출력에는 <eos> 를 넣어, 병렬로 학습한다.
하지만 여기에는 심각한 문제가 있다.
lamb를 예측하기 위해 “I want to eat lamb skewers” 정보를 다 사용한다. “lamb”를 예측하기 위해서는 decoder의 input에서 “I want to eat” 만 사용해야한다. 뒤의 문장들을 쓰면 안된다. 이건 마치 수능 답안지를 외운상태로 수능을 보는 것과 같다. 미래 단어들을 참고하는 것을 막기 위해 Masking을 사용한다.
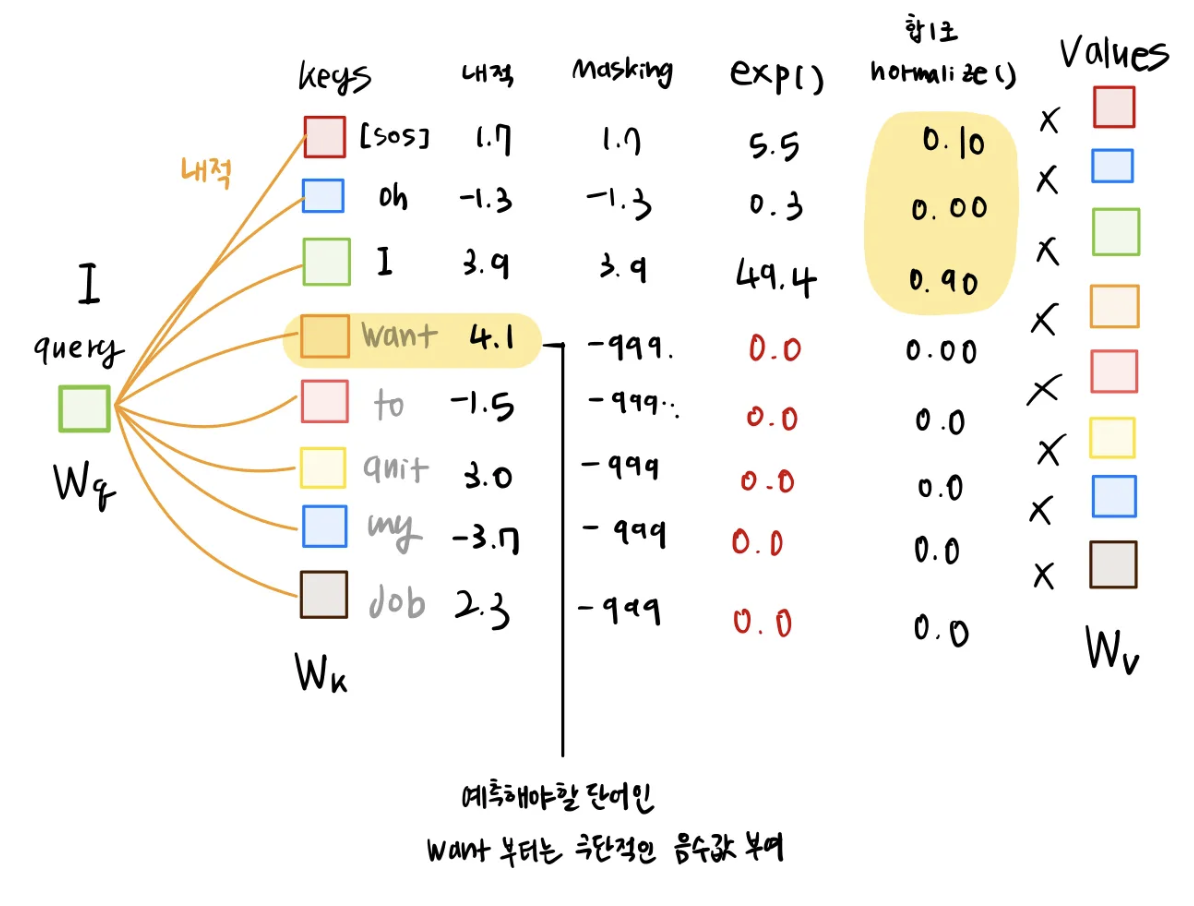
Masking
마스킹은 내적한 결과에 극단적인 음수값을 주는 방식으로 구현한다.